别再只盯着“AO”两家的新模型大战了!谷歌刚刚发布了一款名为DiffusionGemma的新模型线上实盘配资,这款模型将生成图片的扩散模型应用到了文字生成上,并实现了4倍加速。
DiffusionGemma抛弃了传统的自回归模式,即逐个token生成的方式,而是采用类似“印刷机”的工作方式。它一次铺开256个token的“画布”,从随机噪声出发,通过多轮去噪,使整段文字同时浮现。这种新模式在生成速度方面表现出色:单块H100上每秒可生成1000多个tokens,在消费级RTX 5090上也能达到700多个tokens,比同规格自回归模型快了4倍。此外,这个26B参数的MoE模型在推理时只需激活3.8B参数,量化后仅需18GB显存即可运行,一张4090显卡就能本地跑。
目前,DiffusionGemma采用了允许商用的Apache 2.0开源协议,权重可在Hugging Face直接下载。

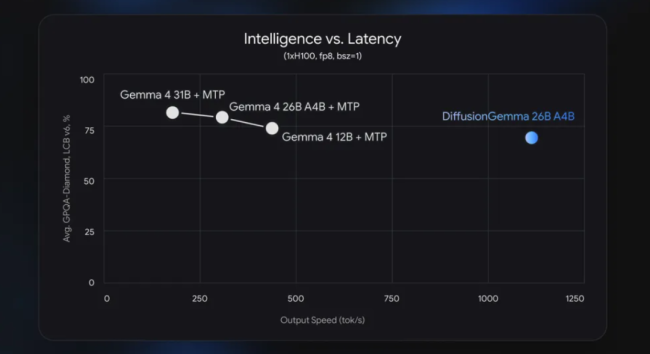
DiffusionGemma的最大优势在于其生成速度。在同一块H100上(fp8,batch size=1),DiffusionGemma的速度达到了1000+ tokens/s,而标准自回归的Gemma 4 26B A4B加上MTP加速也只有300+ tokens/s,速度差距近4倍。
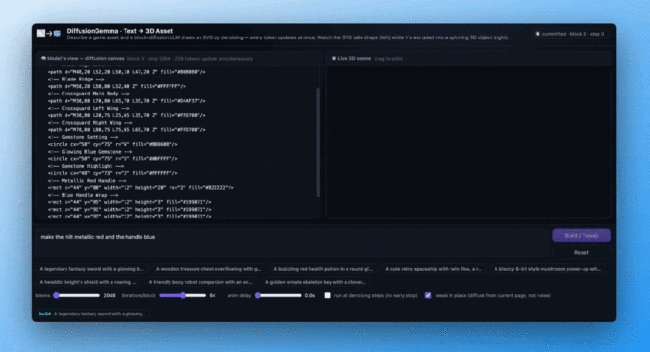
要理解DiffusionGemma为何如此快速,需要了解当前大模型的瓶颈。主流的大模型如GPT、Claude和Gemini都基于自回归架构,每次生成一个新词都要重新加载几十亿参数的模型权重。在云端这不是问题,但在本地运行时,GPU大量算力会空转等待逐字生成,造成内存带宽瓶颈。
为解决这一问题,DiffusionGemma借鉴了图像生成中的扩散模型,一次性对整块token进行并行操作,充分利用GPU的并行计算能力。具体来说,它首先铺开一张全是随机占位符的256个token的画布,然后多轮迭代去噪,高置信度的token先锁定,再用它们作为上下文线索修正其余部分,最终收敛为完整输出。

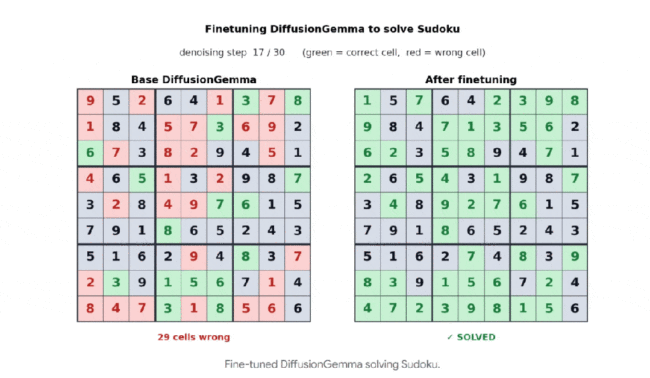
除了速度快,DiffusionGemma还具备双向注意力机制。传统自回归模型只能往前看,而DiffusionGemma每个token都能看到所有其他token,前后文同时可见,从而实现实时自我纠错。例如,在数独任务中,DiffusionGemma微调后的成功率从0%提升到80%。

不过,扩散模型也有局限性,尤其是在速度与质量的平衡上。去噪步数越少速度越快,但质量越差;步数越多质量越好,但速度优势减小。质量方面,DiffusionGemma与同参数量的Gemma 4 26B A4B相比存在差距,因此谷歌建议生产环境使用标准Gemma 4,而DiffusionGemma更适合速度敏感的本地交互场景。
谷歌CEO皮猜表示,DiffusionGemma目前更像一匹“赛马”,旨在探索下一代模型形态。谷歌希望通过这种方式,看看不依赖逐个token生成的情况下,大模型的速度上限能被推到多高。实际上,谷歌并不是第一个尝试这条路的人。早在今年2月,初创公司Inception Labs就发布了扩散文本模型Mercury 2,声称比Claude、Gemini快5到10倍。
谷歌去年I/O大会上展示过Gemini Diffusion实验,当时采样速度达到每秒1479 token,但之后沉寂了一年。现在,DiffusionGemma卷土重来,并得到了NVIDIA从RTX到H100全线的支持。谷歌为其配备了丰富的资源和生态支持,显然不只是为了技术演示。至于DiffusionGemma能否挑战自回归模型的主流地位线上实盘配资,还有待观察。
元鼎证券_元鼎证券官方下载-欢迎下载安装官方APP,轻松使用各项功能提示:本文来自互联网,不代表本网站观点。